Deep Network Structure Suvery
Deep Learning的热潮是由2006年Hinton的DBN引发的,Deep Learning中CNN方向在图像方面的研究热潮也是Hinton组2012年的Imagenet引发的。后面主要就Deep Learning比较出名的结构进行一些介绍。
ImageNet
Geoffrey E. Hinton组于2012年的文章[1]的ImageNet。主要变化如下:
- 卷积层的激活函数使用ReLU,
- 卷积层后面添加LRN(Local Response Normalization)归一化层
- 分类层使用了dropout
- 训练数据增强
OverFea
Yann LeCun组于2013年的文章[2],且其最后网路的输出值可以当着特征来用。其主要使用了其2009年的文章[3]提出来的一些技术来进行网路的构造:
- 卷积层的激活函数使用在传统的Tan函数前面加上一个系数g,即
g*tan(wx+b) - 在卷积层与下采样层之间加入LCN归一化层(或降低计算在下采样层后加LCN)
TCNN
其与2013年在文章[4]中由Bengio组的goodfellow提出的
Maxout Network
其与2013年在文章[5]中由Bengio组的goodfellow提出的
Network in Network
其与2014年在文章[6]中提出的,本质上就是在传统的CNN的卷积层后面再加上一层滤波核大小为1x1的卷积层:
- 使用
MLP(神经网路)代替卷积层中的卷积滤波核,称其为mlpconv, 如下图:
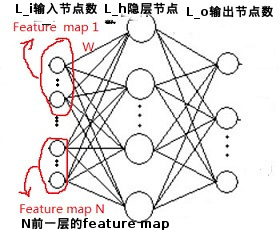
如上图,其将不同的Feature map的相同位置区域组合在一起作为输入,其相当于在传统的CNN的卷积层(NxL_hx滤波核大小)后面再加上一层滤波核大小为1x1的(即L_hxL_ox1x1)的卷积层 - 使用
全局平均采样来代替CNN中的分类器层
即将最后一个Feature Map的大小设为类的个数,然后计算每个Feature Map里平均值,然后丢个softmax,其起到了regularizer的作用。
关于全局平均采样的regularizer的作用,作者做了如下实验 :
NIN + Fully Connected、NIN + Fully Connected+dropout、NIN + 全局平均采样:全局平均采样效果最好CNN + Fully Connected、CNN + Fully Connected+dropout、CNN + 全局平均采样:全局平均采样比全连接好,没有dropout好
VGG
基于Network in Network的扩展实验,使用卷积层加深网路的深度,详细见文章[10]
GoogleNet
其与2014年在文章[7]中基于Network in Network与VGG(文章[10])的改进,使用卷积层加深网路的宽度,其主要目的摘之原文:
The main idea of the Inception architecture is based on finding out how an optimal local sparse structure in a convolutional vision network can be approximated and covered by readily available dense components
Miscellaneous
其他关于网路结构方面的文章[8]
Pre-Train
-
Yann LeCun组基于Deconvolutional Network的思路提出的CPSD
-
Andrew NG组的文章[4]
-
聚类的一种预学习方法文章[9]
Visualization
References
- ImageNet Classification with Deep Convolutional Neural Networks
- OverFeat:Integrated Recognition Localization and Detection using Convolutional Networks
- What is the best multi-stage architecture for object recognition?
- Tiled convolutional neural networks
- Maxout networks, Goodfellow
- Network in Network, Min Li
- Going deeper with convolutions
- An Analysis of the Connections Between Layers of Deep Neural Network
- Clustering Learning for Robotic Vision
- Very deep convolutional networks for large-scale image recognition