PMK(Pyramid Match Kernels)
2006年由Kristen Grauman在文章[1]中提出来的算法,其适用于 unordered、unequal length features
-
Algorithm:
假设特征,即为d维,且每一维的长度为(每个特征的长度可以不一样),即:
这里特征值必须为整数,假设特征值,这里直方图bin的宽度以 2的倍数 增加,则直方图的分辨率,那么
则所有分辨率组合到一起的特征为:
则PMK的相似度定义如下:
一维特征的PMK图形示例如下:
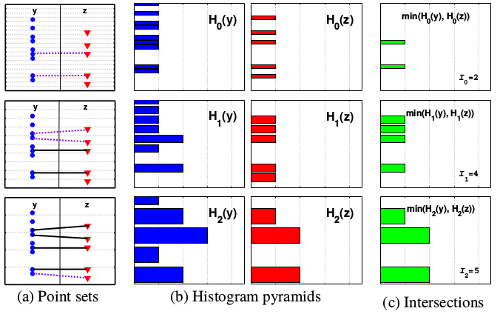
Normalized Version 1:
Normalized Version 2:
- 说明:
- 为Histogram Intersection.
- 需要减去前一层相交,因为前一层的相交在后一层中也相交 .
- 是根据直方图bin的个数来的。d维边长为的超立方体点之间的最大距离为 。 因为i+1层的直方图的bin为i层的一半(即i+1层最大距离是i层的一半),因此的权重也为的一半。 即直方图越精细其权重也越大
- 补充说明:
文章中作者为了解决直方图量化时不同的偏移引入的问题,如下图: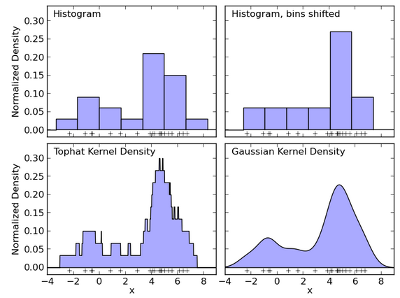
作者在直方图量化时采用多次随机偏移来解决这个问题,即:
Spatial Pyramid Matching
2006年Svetlana Lazebnik在文章[2]中基于文章[1]提出引入空间的信息,即按照 图像的位置信息 来量化直方图,方法如下:
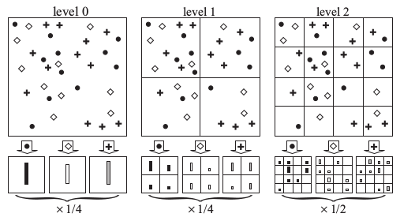
作者在这里引入M中类型的特征,且每个的类型的特征都是2-d的图像,则其公式如下:
- 说明
- 上图中M=3(圆形,菱形,加号)。
- 理论上 可以将上面的PMK的特征直接当成一个2-d的图像来量化,此时M=D.
- 特征的总维度为
- Beyond BOW
文章中作者提出一种超过BOW的特征。基于很多子图像块使用聚类算法,先聚出如200个中心点(即M=200)。然后每幅图像进行二维扫描得到每个子块属于哪个类的索引。基于这个2-D的索引图,得到每个金字塔层的直方图。
References
- Pyramid Match Kernels: Discriminative Classification with Sets of Image Features
- Beyond bags of features: spatial pyramid matching for recognizing natural scene categories