PSD(Predictive Sparse Decomposition)
今天的主题是08-11年比较火热的sparse coding。今天谈的算法是Yann LeCun组Koray
的PSD(Predictive Sparse Decomposition)系列算法。其主要的贡献是在推断过程中不需要再来求解其稀疏表达,而是使用推断函数来得到近似的稀疏表达。
Sparse Coding
传统Sparse Coding的求解过程如下:
由于求解太过复杂,因此采用替代。文章[5]与Convex Optimization一书中证明了,具有同样的效果。因此其求解形式编程了如下形式(Basis Pursuit Denoising):
基于样本集学习的时候,一般是先固定D学习Z,然后再固定Z学习D,如此反复迭代只到收敛。推断时,固定D,通过式(2)求解不同样本的Z,在推断时进行求解显然性能上不允许
PSD(Predictive Sparse Decomposition)
PSD是由Koray2008年在文章[1]中提出的。其主要的思想就是在式(2)后面加上一个推断函数。其cost function如下:
学习时
- 当时,式(3)变成了式(2)。这样先学习得到D、Z。然后再学习得到推断函数的参数
- 当时,学习步骤先固定与D,学习Z,然后在固定Z学习与D。如此反复迭代只到收敛(作者使用梯度下降进行学习)。
推断时,有两种方法求解Z
- 固定B与推断函数,根据式(3)使用梯度下降迭代的求解Z
直接使用推断函数F(x;G,W,B)
Topographic PSD
2009年Koray在文章[2]中基于文章[1]引入了地形学(即相似的特征组织在一起)属性。如下图所示:

其主要思想就是将式(3)中第二项Z的约束变成了一种含有2维性质的约束。如下图所示:
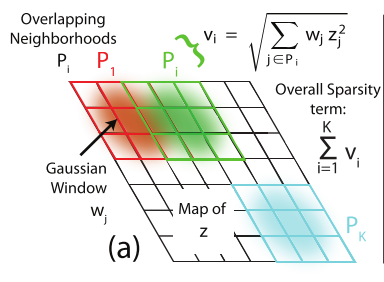
其中有K个重叠的采样窗口(每个为),是固定的高斯分布值。
因此最终式(3)变成了如下式(4):
学习步骤以及推断同上面的PSD。通过作者的实验获得以下一些信息。
- 学习得到的字典D和推断函数中的参数W,
都拥有地形学的属性 - 字典B与推断函数分开学习(即上面PSD学习时的第一种情况),
会导致的推断函数的近似结果不够稀疏,且训练时间加长
Convolutional PSD
2010年Koray在文章[3]中提出的。其主要就是解决了Deconvolutional Networks的求解问题:
一般的sparse coding都是基于图像中的小块(patch)来做的。即上面公式中的Y是图像中的随机子块。
Deconvolutional Networks(文章[4])解决了这个问题,其基于整张图像,Deconvolutional Networks的缺点是对于新的输入X,还要根据D去求解稀疏表达(太耗时间)。Convolutional PSD采用推断函数解决了其求解慢的问题
Convolutional PSD的Loss如下(去掉最后一项就是Deconvolutional Networks的Loss):
应用:
- 训练好的推断函数f的输出可以直接当作z的近似表达。作为分类case下的特征来使用
- 上述方法可以用来作为CNN中卷积核的预学习。即将学习好的推断函数f的中W作为CNN中滤波核的初始值。其结构如下:
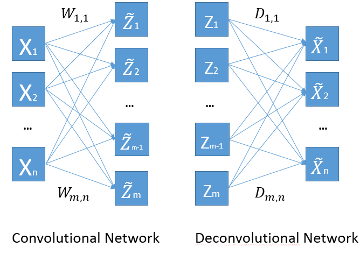
Convolutional network相当于公式中的推断函数。而Deconvolutional network相当于公式中的第一项
训练细节:
在Torhch中的开源代码用的是FistaL1与梯度下降的方法(Get more detail from source code)
1. 固定D与W, 使用FISTA求解得到z
2. 固定z,通过梯度下降基于与分别求解D与W
3. 注意: 公式第一项与第三项中D与W还包含偏移
Reference
- Kavukcuoglu, LeCun. Fast inference in sparse coding algorithms with applications to object recognition. 2008
- Kavukcuoglu, LeCun. Learning invariant features through topographic filter maps. 2009
- Kavukcuoglu, LeCun. Learning Convolutional Feature Hierarchies for Visual Recognition. 2010
- Zeiler, Taylor, Fergus. Deconvolutional Networks. 2010
- DL Donoho and M Elad. Optimally sparse representation in general nonorthogonal dictionaries via l1 minimization